
Clawdbot’s system design explained
Deep, technical teardown of how Clawdbot is designed

Clawdbot hit 100,000 GitHub stars in weeks. TikTok demos went viral. The lobster memes spread everywhere
But strip away the hype, and what remains is one of the most well-architected AI agent systems in the open-source world
This newsletter is a deep, technical teardown of how Clawdbot is designed at the system level.
Each stage in the pipeline isolates a specific class of failures.
Each default chooses safety over cleverness: deterministic execution over accidental concurrency, explicit over implicit, plain files over black boxes.
These are the same system design trade-offs that come up in distributed systems, production architecture, and senior engineering interviews at FAANG. Understanding how Clawdbot solves them will sharpen how you think about designing reliable systems yourself.
PS: This is not a skim. Grab a coffee.
The Core Design Philosophy: Why Clawdbot Is Built as a Pipeline, Not a Chatbot?
Most AI agent frameworks treat the agent as a thinking entity: a brain that receives input and produces output. But not Clawdbot!
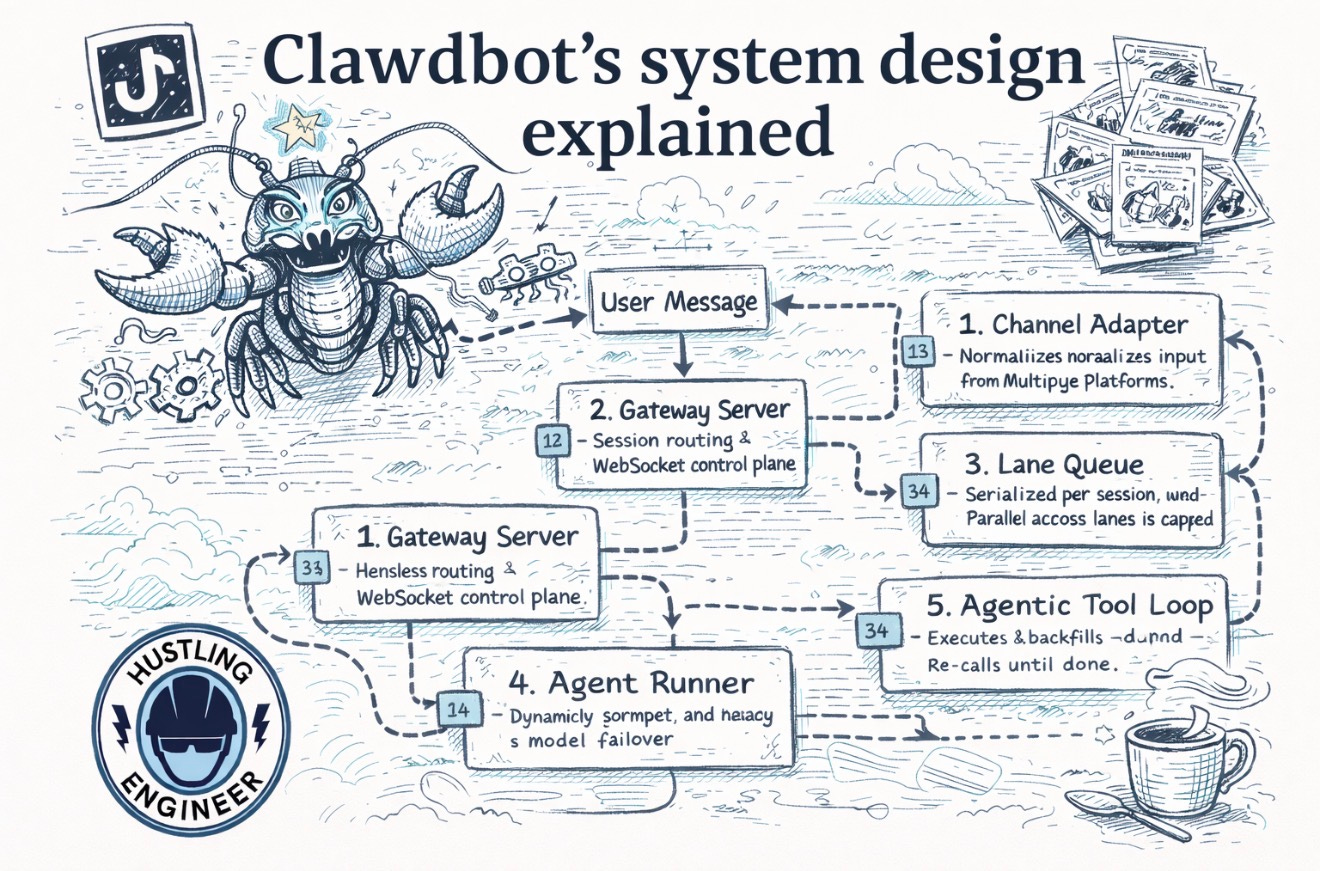
Clawdbot treats the agent as a structured execution pipeline with strict boundaries between stages. Every message passes through six stages in order, and each stage exists to prevent a specific class of bugs.
Here is the full pipeline, end to end:
User Message
│
▼
┌─────────────────────────┐
│ 1. Channel Adapter ← Normalizes input from multiple heterogeneous platforms
└────────────┬────────────┘
│
▼
┌─────────────────────────┐
│ 2. Gateway Server │ ← Session routing + WebSocket control plane
└────────────┬────────────┘
│
▼
┌─────────────────────────┐
│ 3. Lane Queue │ ← Serialized per session lane. Parallel across lanes is capped
└────────────┬────────────┘
│
▼
┌─────────────────────────┐
│ 4. Agent Runner │ ← Dynamic prompt assembly + model failover
└────────────┬────────────┘
│
▼
┌─────────────────────────┐
│ 5. Agentic Tool Loop │ ← Execute → backfill → re-call until done
└────────────┬────────────┘
│
▼
┌─────────────────────────┐
│ 6. Response + Storage │ ← Stream to user + JSONL transcript for audit
└─────────────────────────┘
Every boundary is load-bearing. Remove any one stage, and you get a different category of failure. Let’s walk through each.
Stage 1: Channel Adapters - Why Platform Noise Never Reaches the Agent
Clawdbot integrates with multiple messaging platforms, each with its own payload formats, media handling, and event semantics.
Rather than letting that complexity leak inward, every platform is isolated behind a dedicated channel adapter.
Each adapter performs two responsibilities:
Message normalization: Platform-specific payloads are transformed into a single internal message envelope before entering the system.
Attachment extraction: Media, documents, and voice inputs are converted into a consistent representation that downstream stages can process without caring about origin.
The agent core never sees stickers, embeds, reactions, or platform-specific metadata. It receives a clean, uniform input every time.
This boundary prevents platform quirks from contaminating execution logic and allows new channels to be added without touching the agent or tool layers.
Stage 2: The Gateway Server - One Control Plane to Rule Everything
The Gateway is Clawdbot’s central nervous system. It runs as a long-lived daemon on localhost:18789 and exposes a typed WebSocket API.
It enforces a strict protocol contract. Every client connection follows a defined handshake sequence, and every request is validated against schema-defined message types before being processed. Frames that violate the protocol or authorization requirements trigger an immediate hard close.
The Gateway server is responsible for:
Session routing: Incoming messages are mapped to sessions based on chat context and configuration, ensuring that direct messages, group chats, and separate identities remain isolated from one another.
Device pairing: Every connecting client (CLI, desktop app, or remote node) presents a device identity. New devices require pairing approval via a challenge–response mechanism, with approval behavior determined by security configuration.
Event coordination: The Gateway acts as a central control plane, emitting structured events that subscribed clients use to stay synchronized with agent state, chat activity, and system health.
By centralizing request validation and ordering in a single control plane, Clawdbot prevents an entire class of state-corruption and coordination bugs before they can occur.
Stage 3: Lane Queues - The Most Underrated Design Decision
Most agent systems let concurrency happen accidentally: messages arrive, runs overlap, logs interleave, and shared state gets corrupted in ways that are hard to reproduce.
Clawdbot avoids that by using a lane-aware FIFO queue.
Each chat maps to a session key, and every run for that session is queued in a dedicated lane, such as session:<key>, which guarantees only one active run per session at a time.
At the same time, the system is not globally serialized. Different lanes can run in parallel, but parallelism is deliberately bounded by concurrency limits (for example, overall caps such as agents.defaults.maxConcurrent, and default lane caps like main and subagent concurrency).
This design gives you the best of both worlds:
No overlap inside a single conversation, so state and logs stay ordered.
Controlled throughput across conversations, so the system can handle multiple chats without turning into a race-condition machine.
This choice looks boring on paper but saves hundreds of hours in production.
Stage 4: Agent Runner - Dynamic Prompt Assembly, Not Static Templates
The Agent Runner does far more than call an LLM.
Model selection and failover: Selects providers and API keys, enforces failure cooldowns, and automatically falls back to alternate models. Auth rotates between OAuth and API keys.
Dynamic prompt assembly: Builds the prompt at runtime from system instructions, active tools, loaded skills, retrieved memories, and session history from the JSONL transcript.
On-demand skill loading: Skills enter the prompt only when enabled, avoiding unnecessary context window costs.
Context window guard: Tracks token usage before each call. When limits are approached, the system runs a compaction step that persists durable memory before summarizing session history.
Stage 5: Agentic Tool Loop
Every model call ends in one of two outcomes:
The model returns a final text response, and the run completes.
The model returns a tool call.
If the model emits a tool call, execution enters the agentic tool loop.
In that loop, the tool runs within the agent’s configured execution context, which may be restricted or sandboxed based on policy. The tool output is then converted into a structured observation, appended back into the session context, and the model is called again with the new state.
That execute → observe → backfill → re-call cycle repeats until the model produces a final response or a turn limit is reached. This is where real autonomy comes from, and also where most systems fall apart if the loop isn’t bounded.
All external side effects happen here: shell commands, browser actions, file operations, and network calls. Autonomy exists only inside this bounded loop, which keeps execution predictable and inspectable.
Stage 6: Response and Durable Storage - Making Every Run Replayable
Once the agent produces a final response, execution ends, and the system enters the finalization stage.
It is responsible for:
Streaming the final response back to the user
Writing an append-only JSONL transcript of the entire run
Persisting durable markdown memory when the agent decides something should survive beyond the session
Emitting completion events to subscribed clients
Every interaction becomes a replayable, auditable artifact. Nothing is lost, silently dropped, or hidden inside opaque services.
By separating execution from persistence, Clawdbot ensures that failures in storage never corrupt reasoning, and failures in reasoning never compromise the audit trail.
Why Does Clawdbot Use Plain Files Instead of a Database for Memory?
Clawdbot avoids complex memory stacks in favor of explicit, inspectable storage. The system uses two memory layers:
JSONL transcripts: Append-only audit logs of user messages, tool calls, and results. Each line is a complete interaction unit, making runs replayable and debuggable.
Markdown long-term memory: Durable notes stored as plain files (for example, in a memory/ directory). The agent writes these via standard file tools, keeping memory human-readable and version-controllable.
Both layers are queried together using semantic similarity when embeddings are available, and keyword search (FTS5/SQLite) is used to preserve exact terms and error strings.
Embedding providers are tried in explicit priority order (local first), and semantic retrieval is disabled rather than degraded if none are configured.
There is no decay curve. Old memories do not disappear. The entire history remains version-controllable and inspectable months later.
Can You Architect Systems Like Clawdbot? That’s What Gets You to $300K+ Roles in FAANG
If you followed the Lane Queue logic, understood why the Gateway enforces a single control plane, or saw why semantic snapshots beat screenshots, you just did something most engineers never practice: you reasoned through a real system’s design trade-offs from first principles.
That is the exact skill that separates a mid-level engineer from a senior one.
I see this gap constantly. Engineers with 3, 5, and even 8 years of experience who can build features but cannot articulate the architecture behind what they built. They grind DSA for months, walk into a system design round at Meta or Google, and freeze — not because they lack skill, but because no one taught them how to think at this level.
That is why I built a 5-week mentorship cohort specifically for mid-level engineers who want to break into $300K+ / ₹50L+ senior roles at FAANG and top startups.
Inside the cohort, you get:
Constraint-first system design frameworks
Clear trade-off and failure-mode discussions
Guided think-out-loud interview practice
Analysis with resume feedback
A focused plan for DSA, LLD, HLD, and behavioral rounds
Job search and referral strategy to improve interview access
1:1 guidance for course correction
The system design thinking you just practiced reading this newsletter? That is a small window into the kind of reasoning we build systematically across five weeks of this cohort.
Register here to receive a callback from my team at Topmate so they can clear all your doubts before you enroll in the cohort:
https://share-na2.hsforms.com/1QTqiYZoFSoaySnFrOp3uiQ41clik
– Hemant Pandey
Senior Software Engineer at LinkedIn
Ex-Meta, Salesforce, Tesla
Helping engineers break into senior roles at FAANG